October 21, 2016: a Harcros Chemicals delivery truck arrives at the
MGPI Processing plant in Atchinson, Kansas for a routine early-morning
delivery of sulfuric acid. Together with a plant operator, the driver
runs a hose from their trailer tank of pressurized sulfuric acid to one
of the facility’s fill lines, checks for leaks, and starts the transfer
of acid.
Not fifteen minutes later, a yellow-green cloud erupts from one of
the facility’s holding tanks. It swallows the delivery truck. It engulfs
the nearby control building; the operators scramble from the plant on
foot. The driver takes refuge in a wastewater treatment plant nearby,
and the green cloud — highly toxic chlorine gas — drifts northeast, on
the wind, over Atchison.
How does a routine delivery cause an uncontrolled release of
chlorine? Through a reaction between the delivered acid and a tank of
sodium hypochlorite. At the MGPI plant, stocks of these two
“incompatible” chemicals are loaded from the same connection area, using
an identical hose connection. The driver connected to the wrong
unmarked fill line.
“Neither sodium hypochlorite nor sulfuric
acid fill lines had pipe markers or identification tags affixed at
connection points.”1
Anyone who’s done their time on a rushed software engineering team
has cleaned up an analogous accident: two things, usually separated, are
mixed by accident or mistaken design.
What did it cost you? A couple hours of work and some griping in
Slack? For a chemical process engineer (or any other species of
real engineer), the stakes are astronomically higher. We have
much to learn.
Industrial chemical accidents in the U.S. are subject to
investigation by the U.S. Chemical Safety and Hazard Investigation Board
(USCSB). According to their report, the Atchison incident teaches a “Key
Lesson:” if components should never be connected, make it impossible to
connect them!
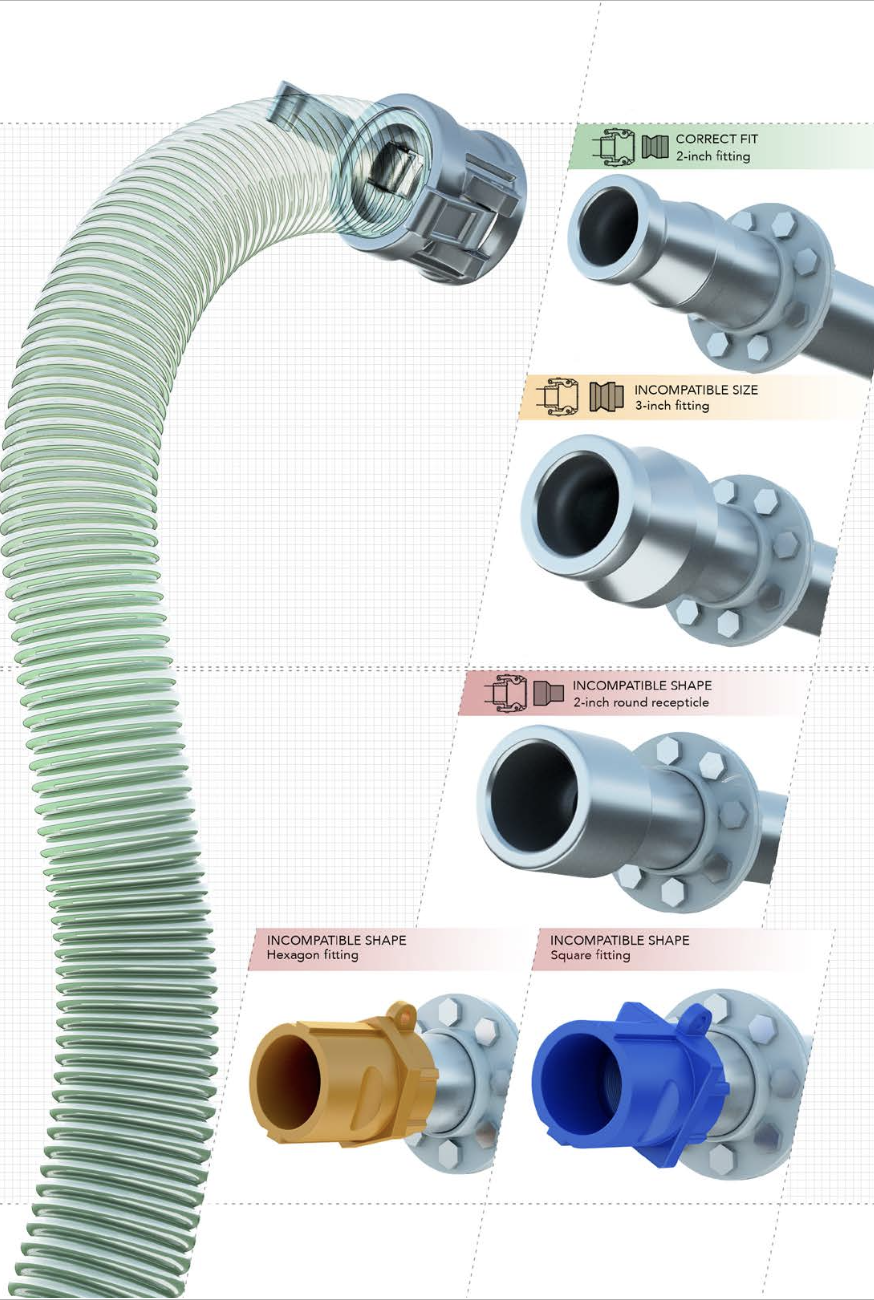
Work with chemical distributors to select hose couplings and fill
line connections with uniquely shaped and color-coded fittings for each
chemical or class of chemicals, especially where severe chemicals
are unloaded in close proximity. This can include a combination of
accepted fittings with unique shapes (e.g., square for acids, hexagon
for bases) or different sized diameters (e.g., 2-inch or 3-inch round)
for each fill line.2
Figure 10. Combination
of fill line shapes and sizes to avoid incorrect connections during
deliveries (Source: CSB).
An early-career software engineer generally works additively. One
starts with some raw stuff (an empty project structure, then some
language primitives, some data…) and accrues features and affordances
until the program is at least capable of completing some
task.
Considering capabilities as hazards doesn’t come as
naturally, even though examples abound. There are examples in our
ancient jokes: rm is hazardously compatible with your
precious root directory. That’s fine for a library, but death in a
system3 — you don’t need an API endpoint
that drops your production database, even though your database libraries
could do so.
Unfortunately for our safety analysis, the raw stuff of
software engineering is less definite than the raw stuff of chemical
plants (you know, the chemicals).
One valuable analogy is types. A function’s parameters are
its fill lines — they constrain what sorts of data can be pumped into
it. Whereas chemical process engineers use incompatible hose couplings,
programmers can elect to use incompatible types to avoid
mix-ups.
Strongly
typed identifiers are a classic example of this principle. While
there’s some underlying primitive type (e.g. an integer representing
auto-incrementing IDs, or a string representation for a UUID4) it’s categorically incorrect to use
an ID from one table to perform a lookup in another.
You can incorrectly mix IDs from different tables in queries, of
course. Consider this buggy SQL query:
SELECT cart.id, cart.customer_idFROM customers AS customerJOIN carts AS cart-- This *should* match cart.customer_id to customer.id, but doesn't.ON customer.id= cart.id;
A library may allow this kind of mistake, but your program shouldn’t.
A good ORM should support strongly typed identifiers out of the box. You
may need to carefully massage raw ID representations into the correct ID
types at your system boundaries (e.g. in your API handlers), but then
you can code within that boundary without paranoia.
These kinds of mistakes happen. They make nightmarish bugs:
updates meant for one entity are applied to an arbitrary other entity in
its table (Customer A adds an item to Customer B’s cart — yikes!). They
also slip through code review, especially in tandem with
over-abbreviated variable names. A team I worked with recently switched
to typed IDs, and uncovered a handful of these bugs in
production, tucked away in sleepy code-paths where their filthy
impact went unnoticed.
// Less safe: inadvertent mixing.func unsafeDeleteCustomer(id int){...}func unsafeOperation(c Cart){// Compiles, but uses a cart ID to look up a customer. unsafeDeleteCustomer(c.id)}// More safe, and more expressive to boot!func deleteCustomer(id CustomerId){...}func operation(c Cart){// Compiler error! c.id is not a CustomerId. deleteCustomer(c.id)}
This type-level safety through incompatibility is the generalized
response to the code smell Martin Fowler terms “primitive obsession.”5 Using proper closed enums
over grab-bags of named values is another neat example; as for typed
IDs, a good ORM and a good database schema do much of the heavy
lifting.
Other incompatibilities are more specific to your system, your
business logic, or the quirks of the data you inherited; these are
harder to spot, but just as important. I recently worked on a system
where two different sources of activity data were keyed differently:
Granular transactions, dated by when they
occurred.
Daily summaries, dated by when they are
generated. The summary with date August 10, 2024
actually summarizes transactions dated to
August 9, 2024!
The difference in those dates — a poor data model design, to be sure
— was a constant stumbling block for new engineers: it seemed like the
two dates would naturally correspond, but treating them interchangeably
(comparing them to join sets of transactions with
summaries) is completely misleading!6
We initially tried to solve this with what the USCSB would term an
“administrative control:” authors were expected to understand the
difference between the two dates, and reviewers were expected to confirm
they were used correctly. Even if you can remember to do it, this is
hard code to refactor. That activityDate argument date your
function receives — what kind of date is it? Has it already been
shifted?
Selective incompatibility proved a stronger solution. These were both
dates, sure, but they should not mix. Define two wrappers for
date types — SnapshotDate and TransactionDate
— that can’t be directly compared. Instead, define projections from one
type into the other.
The higher-level lesson for a software engineer reading the Atchison
incident report isn’t specific to “accidental mixing” (whether acids or
IDs). This incident analysis, with its parallels in software,
illustrates the value of drawing safety lessons from older, more
spectacularly dangerous engineering disciplines.7
There is nothing new under the sun.
Nothing new for process safety engineers, either.
Trevor Kletz’s 1985 Engineer’s View of Human Error describes
“wrong connections.” His explanation of the concept gives an example
from the dawn of anesthesia:
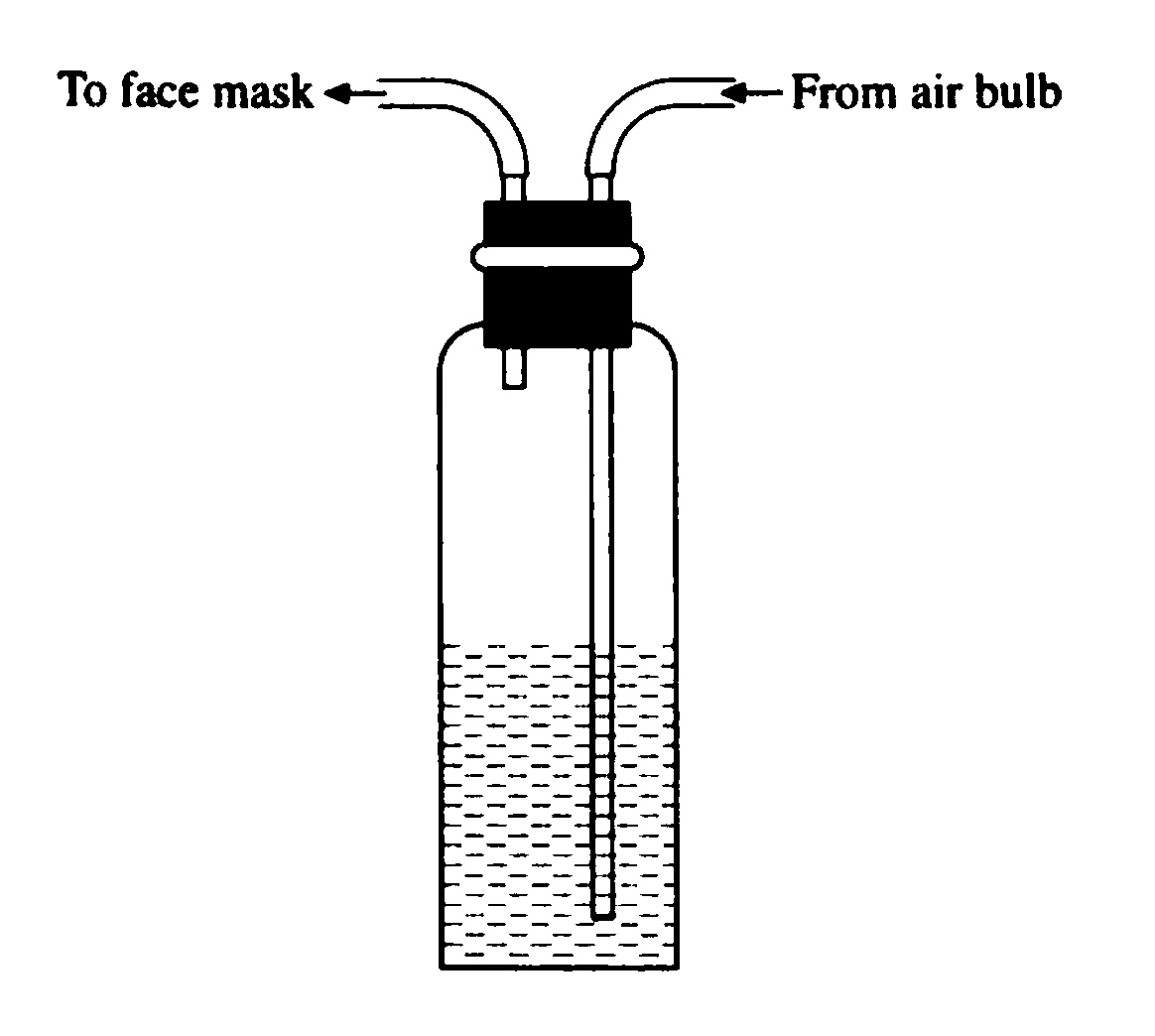
Figure 2.13 shows the simple apparatus devised in 1867, in the early
days of anaesthetics, to mix chloroform vapour with air and deliver it
to the patient. If it was connected up the wrong way round liquid
chloroform was blown into the patient with results that could be fatal.
Redesigning the apparatus so that the two pipes could not be
interchanged was easy; all that was needed were different types of
connection or different sizes of pipe. Persuading doctors to use the new
design was more difficult and the old design was still killing people in
1928. Doctors believed that highly skilled professional men would not
make such a simple error but as we have seen everyone can make slips
occur however well-motivated and well-trained, in fact, only when
well-trained.8
Figure 2.13 It was easy
to connect it up the wrong way round and blow liquid chloroform into the
patient.
The book’s third edition (2001) includes another example:
Do not assume that chemical engineers would not make similar errors.
In 1989, in a polyethylene plant in Texas, a leak of ethylene exploded,
killing 23 people. The leak occurred because a line was opened for
repair while the air-operated valve isolating it from the rest of the
plant was open. It was open because the two compressed air lines, one to
open the valve and one to close it, had identical couplings, and they
had been interchanged. […]9
The problem wasn’t solved in 1989, and it wasn’t solved in 2016; I’d
bet the U.S. still hasn’t consigned inadvertent mixing accidents to
history. The ultra-serious process engineers are still learning from
their past mistakes. So should we — from their mistakes and
ours.